You AutoComplete Me
Part 1: Into
Auto Complete: Summary
Back in 2018, I was given the task to improve our autocomplete experience. We already had an Autocomplete backend solution using Elasticsearch, but what we needed was something that was faster, more customizable which could handle complex queries such as red bmw x5 in napa 2019. This is the story of how I approached it, what I learnt, and the final product that it came to be, using a pure Python solution! In this talk the user will get familiar with various data structures in Python, from the built-in deque to creating Trie-tree and Directed Acyclic Word Graph (DAWG) and even fuzzy matching via phonetic algorithms and Levenshtein edit distance. We also explore the grey area between incremental search and delimited search. Finally, a package called fast-autocomplete is introduced which we already use in production and are very excited to get it into the wild.
What is Autocomplete
Did you know we can categorize search into 2 types?
- Delimited Search: You type something, hit enter and get results.
- Incremental Search AKA Auto Complete AKA Auto Suggestion: As you type text, possible matches are found and immediately presented to the user.
It gets even more interesting. Jef Raskin, who conceived the Macintosh project at Apple, wrote in his The Humane Interface book that I can see almost no occasions when a delimited search would be preferred [over autocomplete].
I mean, let’s be honest. Unless you really know what you are searching for, you expect the autocomplete to guide you these days, no?
Part 2: Autocomplete: How?
1. Trie-Tree (Radix Tree, Prefix Tree)
https://en.wikipedia.org/wiki/Trie
Trie-Tree is one of the most common ways to do autocomplete. The graph is structured such that a node is a word or a flag that means “add up the edges”, an edge is a letter of a word.
Here is an example:

As the user types each letter, the algorithm traverses through the graph, moving from node to node. At each node, all descendants of that node are displayed. For example, if the user typed bm, the descendants bmw, bmw x5, and bmw x3 are returned.
Trie-Tree in Python
So how would we do this in Python? What about making a node class?
class Node:
def __init__(self):
self.children = ?Hmm, the children are the other nodes. And what connects one node to the other? Yes, the letters are the edges!
a letter
node 1 -----------> node 2A letter maps one node to another. Yes, mapping, or what Python calls a dictionary!
class Node:
def __init__(self):
self.children = {}While we are here, let’s add an attribute to hold the optional full word for the node too.
class Node:
def __init__(self):
self.children = {}
self.word = NoneInserting into the tree
When we insert a word, we want to insert the letters one by one and create a node if we don’t already have it:
class Node:
def __init__(self):
self.children = {}
self.word = None
def insert(self, word):
node = self
for letter in word:
if letter not in node.children:
node.children[letter] = Node()
node = node.children[letter]
node.word = word
return nodeTraversing the tree
We can follow the same logic as above for traversing. We traverse starting from the current node until we have exhausted all of the letters in the query or we reach a dead-end in our graph.
def traverse(self, query):
node = self
for letter in query:
child = node.children.get(letter)
if child:
node = child
else:
break
return nodeNow let’s add some __repr__ to the node for easier debugging. Here is the whole thing together:
class Node:
def __init__(self):
self.children = {}
self.word = None
def insert(self, word):
node = self
for letter in word:
if letter not in node.children:
node.children[letter] = Node()
node = node.children[letter]
node.word = word
return node
def traverse(self, query):
node = self
for letter in query:
child = node.children.get(letter)
if child:
node = child
else:
break
return node
def __repr__(self):
return f'< children: {list(self.children.keys())}, word: {self.word} >'Let’s look at the example graph again:
Let’s traverse now:
WORDS = ['bmw', '2018', 'x3', 'x5', 'bmw x5', 'bmw x3', 'napa']
root = Node()
for word in WORDS:
root.insert(word)>>> root.traverse(query="bm")
< children: ['w'], word: None >So far so good: we got to the node which has the w edge which links to the bmw node.
What if we type something that is not in the graph?
>>> root.traverse(query="bmq")
< children: ['w'], word: None >The traverse function stops when it can no longer find an edge with the requested letter (“q” in the above example). And if we type a full word that is in the graph:
>>> root.traverse(query="bmw")
< children: [' '], word: 'bmw' >Nice! However, this has not “completed” anything for us yet. It has only traversed to a node. In order for it to make a “completion”, we want to get all of the descendants of the current node.
How do we get all the descendant nodes of bm? Using recursion we get bmw x5, then bmw x3, and finally bmw. But it makes more sense if the nodes closer to the root of the tree are returned first. Implementing a breadth-first strategy can be useful for that.
Breadth-first
Queue.Queue vs. collections.deque
We can employ breath-first search by using a queue. Python comes with the Queue.Queue module but it is not useful in this context: Queue was made to enable threads to communicate using queued messages. What we need to use is collections.deque, which is just a data-structure. It has O(1) complexity in appending and popping from both ends.
def get_descendant_nodes(self):
que = collections.deque()
for letter, child_node in self.children.items():
que.append((letter, child_node))
while que:
letter, child_node = que.popleft()
if child_node.word:
yield child_node
for letter, grand_child_node in child_node.children.items():
que.append((letter, grand_child_node))Great! Now we can return actual autocomplete results!
>>> found_node = root.traverse(query='bm')
>>> list(found_node.get_descendants_nodes())
[< children: [' '], word: bmw >, < children: [], word: bmw x5 >, < children: [], word: bmw x3 >]Synonyms
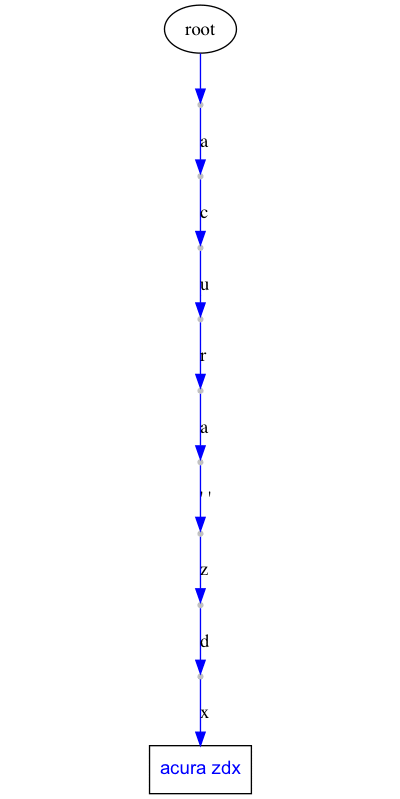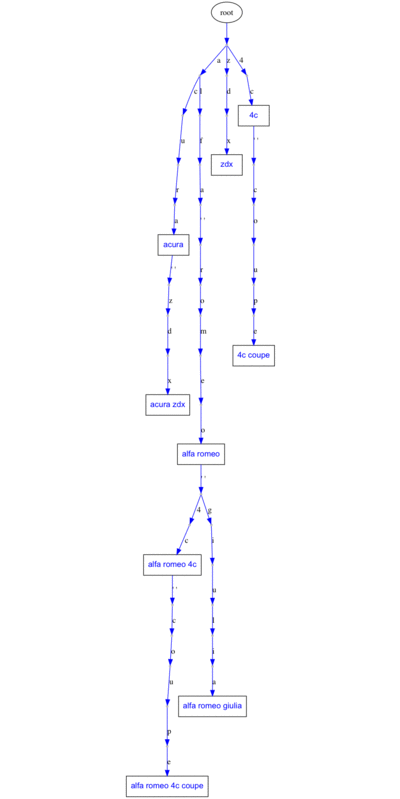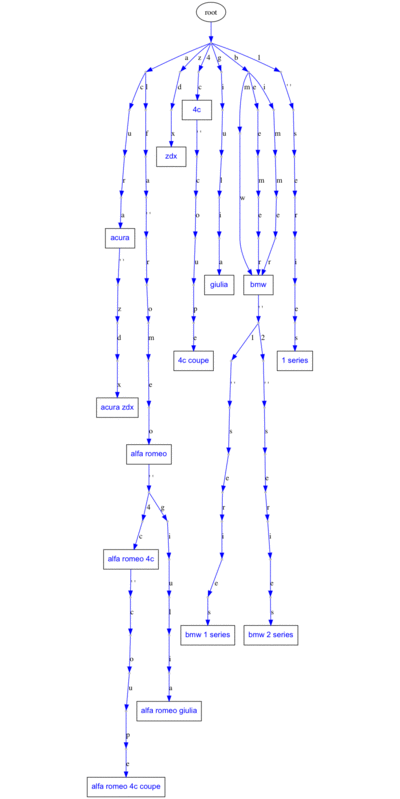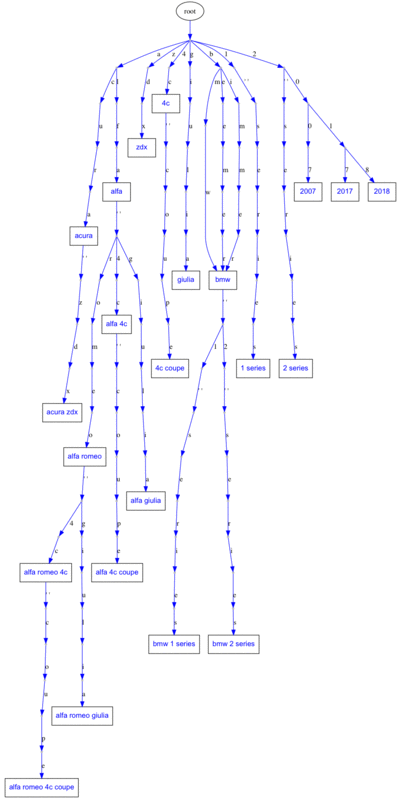
It turns out that there are people out there who call bmw, bimmer. By using Trie-Tree, we can have completely separate branches for the same thing: bmw and x5.
It seems like a waste of space to have bmw and x5 at 2 different branches in the trie. What if we could combine these 2 branches into one? That’s where DAWG comes in.
Before adding synonyms:
After adding synonyms:

And this is just the tip of the iceberg. What if we join branches where the words mean the same thing?
2. Directed Acyclic Word Graph (DAWG, Deterministic Acyclic Finite State Automaton)
A DAWG is very similar to a trie-tree except that the branches can merge back to each other! So it is not a trie anymore: it is an acyclic graph. Take a look at how much space we can save by merging branches that mean the same thing:

To change our trie-tree into a DAWG, we will give the insert method the ability to set the word attribute of the node:
def insert(self, word, add_word=True):
node = self
for letter in word:
if letter not in node.children:
node.children[letter] = Node()
node = node.children[letter]
if add_word:
node.word = word
return nodeNow when we add words we can manually merge branches when there are synonyms:
SYNONUMS = {'bmw': 'beemer'}
root = Node()
for word in WORDS:
synonym = SYNONUMS.get(word)
if synonym:
inserted_node = root.insert(word)
inserted_synonym = root.insert(synonym[:-1], add_word=False)
inserted_synonym.children[synonym[-1]] = inserted_node
else:
root.insert(word)Great! Now we can return actual autocomplete results for synonyms:
>>> found_node = root.traverse(query='beem')
>>> list(found_node.get_descendants_nodes())
[< children: [' '], word: bmw >, < children: [], word: bmw x5 >, < children: [], word: bmw x3 >]DAWGs are very useful to eliminate suffix redundancy. However, one of the drawbacks of DAWG is that there can be several paths to get to the same node. So if it is important how you get to a node, it could cause some problems.
What we are doing here is just touching the surface of what DAWGs can offer and how much space they can save. For example, the DAWG package written by Mikhail Korobov can reduce memory usage for a list of 3 million words by a factor of more than one hundred percent!!
Python list: about 300M
dawg.DAWG: 2MYou can read more about DAWG here: https://en.wikipedia.org/wiki/Deterministic_acyclic_finite_state_automaton
Now that you are familiar with Trie and DAWG, let’s step back and think about them for a second. When the user for example types bmw x5 na, we get to the leaf node that has bmw x5, but there is nothing else left in the branch to traverse. Now what? How can we recommend napa to them?
One way to solve it is using Markov chains:
3. Markov Chain
Another interesting way to create autocomplete is using Markov chains:

Imagine that we feed a corpus of text into a system where it keep tracks of how many times any two words follow each other. Based on that we come up with the probability of which word follows which. Using these probabilities, we can give autocomplete suggestions to users based on the most historically common co-occurring words.
There is a Python library that does this for you by Rodrigo Palacios: https://github.com/rodricios/autocomplete
pip install autocomplete
autocomplete.predict('the','b')
[('blood', 204),
('battle', 185),
('bone', 175),
('best', 149),
('body', 149),
...]To read more about Markov chains take a look at: https://en.wikipedia.org/wiki/Markov_chain
Summary of methods
Before we continue, let’s summarize what we have gone through.
- Trie-Tree: Simple but not space efficient
- Directed Acyclic Word Graph (DAWG): More complicated, very space efficient
- Markov Chain: Based on probabilistic relationships between words, not character to character.
Part 3: Dealing with mis-spellings
Option 1: Fat-Finger Error
Let’s assume the person knows what they want but presses the wrong key next to the key they meant to press. The Python Autocomplete package by Rodrigo Palacios (the one that uses Markov Chains) addresses this scenario. All you need is a dictionary that maps each character with all of its neighboring characters on a typical keyboard.
NEARBY_KEYS = {
'a': 'qwsz',
'b': 'vghn',
'c': 'xdfv',
'd': 'erfcxs',
...
}You can then traverse whichever search algorithm you are using with each of these “fat-finger error” alternatives.
Option 2: Instead of using the original characters as the edges of the graph, use phonetic algorithms
Metaphone or Soundex:
These are phonetic algorithms for indexing words by their sound. Words that sound the same will have the same code!
For example there is a jellyfish package.
In [1]: import jellyfish
In [3]: jellyfish.metaphone(u'bmw 3 series')
Out[3]: 'BM SRS'
In [4]: jellyfish.metaphone(u'bmw 3 seris')
Out[4]: 'BM SRS'If what user enters and what is in the graph sound the same, it works perfectly!
In this case we would have put BM SRS as an edge in the graph and the word at that node would have been bmw 3 series.
The problem with this approach is that:
In [5]: jellyfish.metaphone(u'bmw 4 seris')
Out[5]: 'BM SRS'In our case, those are two different models!
Option 3: Levenshtein Edit Distance
Levenshtein Edit Distance gives you the minimum number of operations required to transform one word into another:
- kitten → sitten (substitution of “s” for “k”)
- sitten → sittin (substitution of “i” for “e”)
- sittin → sitting (insertion of “g” at the end).
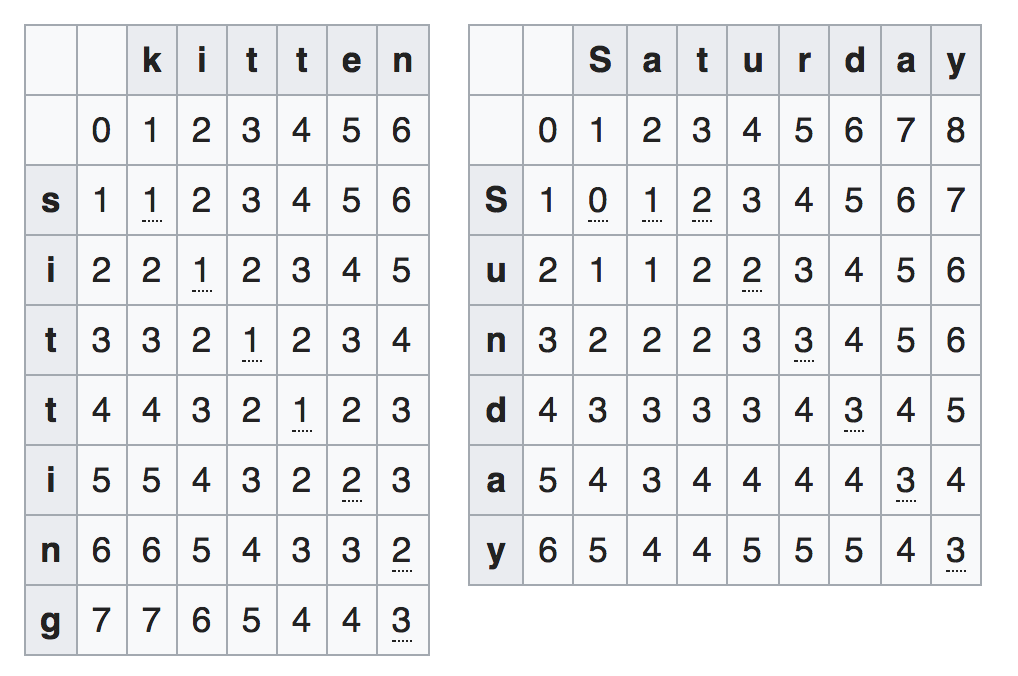 Photo courtesy of Wikipedia
Photo courtesy of Wikipedia
And there is a Python Levenshtein package that can calculate the distance for you. The jellyfish package has its own implementation of the algorithm too.
Part 4: Switching our Autocomplete from Elasticsearch to Fast-Autocomplete
At this point this was an experimental/research project. We had already an autocomplete service that was using Elasticsearch but…
Issue: speed and errors on Elasticsearch
Take a look at this diagram to see what was going on. There were errors from time to time, and there were times that the latency was above a second!
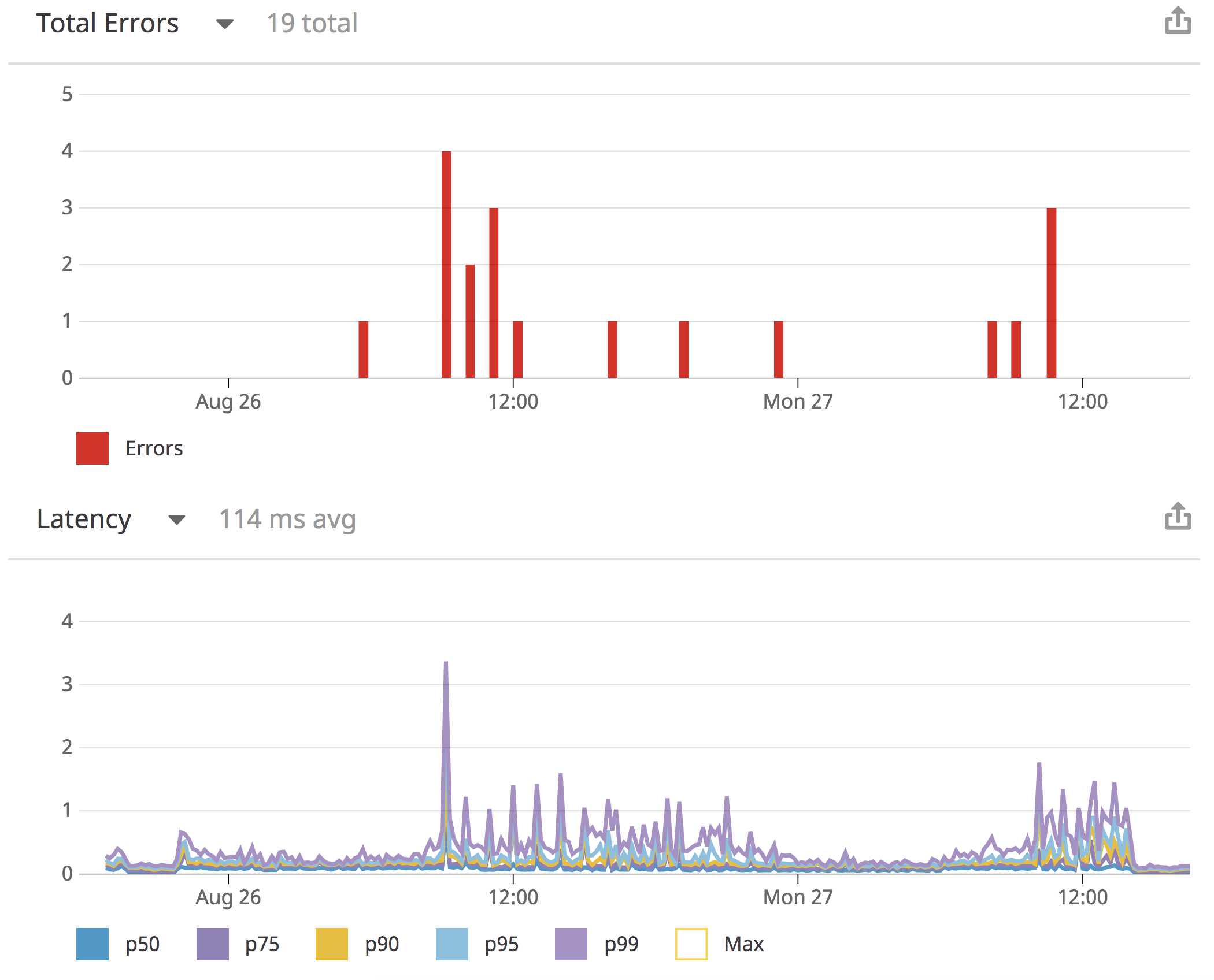
And the service couldn’t handle complex queries. In order to have red bmw x5 2019 in Napa you had to put the whole sentence as an option in Elasticsearch.
What else is out there?
At this point the main contender was what Elasticsearch is built on: Lucene. Lucene is the Java library that has a Python wrapper called PyLucene.
Lucene gives you 3 options for Autocomplete: http://lucene.apache.org/core/7_2_0/suggest/index.html
- JaSpell-based autosuggest, which is based on Java Spelling Checking Package.
- Ternary Search Tree based autosuggest. This is something we didn’t discuss here but is more efficient than Trie-Tree. Basically it is a Tree within a Trie. Here is an interesting post about it by Igor Ostrovsky: http://igoro.com/archive/efficient-auto-complete-with-a-ternary-search-tree/
- And finally Finite-state based autosuggest. Yes, Lucene implemented DAWG for autocomplete too!
Both Lucene and PyLucene are Apache projects. Surprisingly I could not find good documentation for how to use PyLucene. Plus I had to run a JVM to run Lucene itself and deal with managing the JVM.
That was the point that decided to take matters into my own hands.
The answer is: Build from scratch
Introducing fast-autocomplete
Using the DAWG data structure, Levenshtein Edit Distance, and LFU caching.
pip install fast-autocomplete
https://github.com/seperman/fast-autocomplete
Thanks to graphviz, it can even create an animation of words insertion!
# word = dictionary of words to their contexts
# synonyms = dictionary of words to their synonyms
from fast_autocomplete import demo, AutoComplete
autocomplete = AutoComplete(words=words, synonyms=synonyms)
demo(autocomplete, max_cost=3, size=5)You might ask what did you decide to do when the algorithm ends up on the leaf of a branch? How do you get from bmw x5 to bmw x5 in napa ?
Part 5: Dealing with sentences
Markov Chains vs. Looping through the graph
Coming back to our problem of how to recommend Napa once we reached the leaf node in the graph while searching for bmw x5, Markov Chains could have been a great solution. I said they “could” if and only if we had a corpus of text to extract all sorts of words related to cars, which we could use to get the co-occurring probabilities of which words follow which. However since I did not have such a corpus of data, I decided not to use Markov Chains. Instead, the approach I took was to go back to the root node and continue traversing from the root any time we have reached a dead-end on a leaf node.
And here we go!
part 6: Demo
demo 1
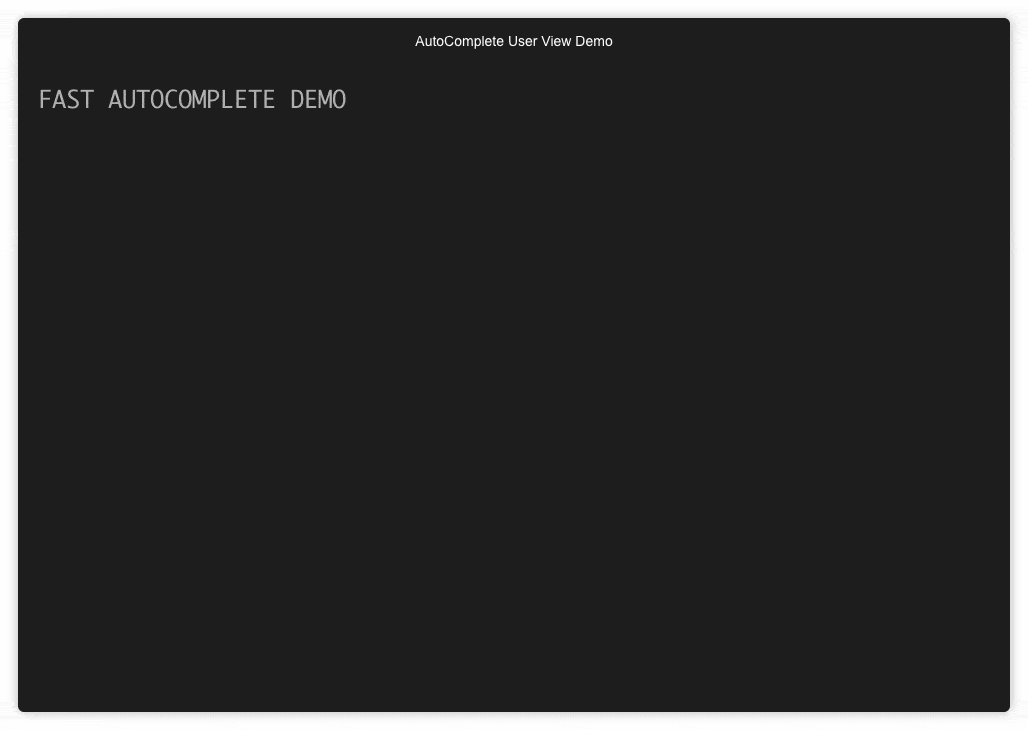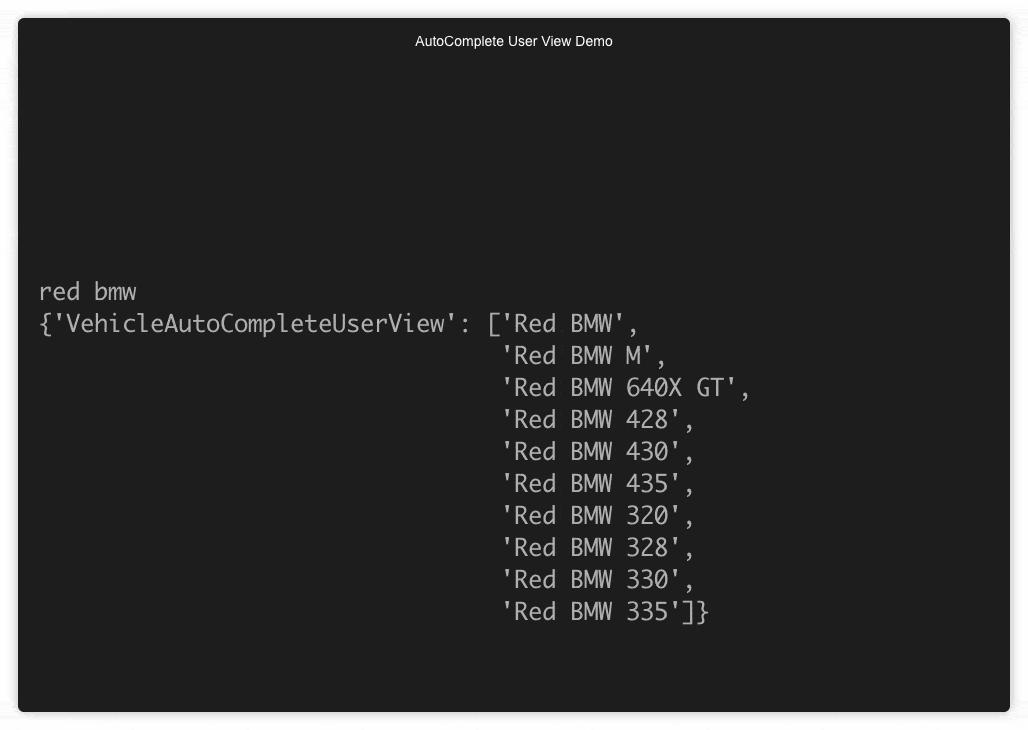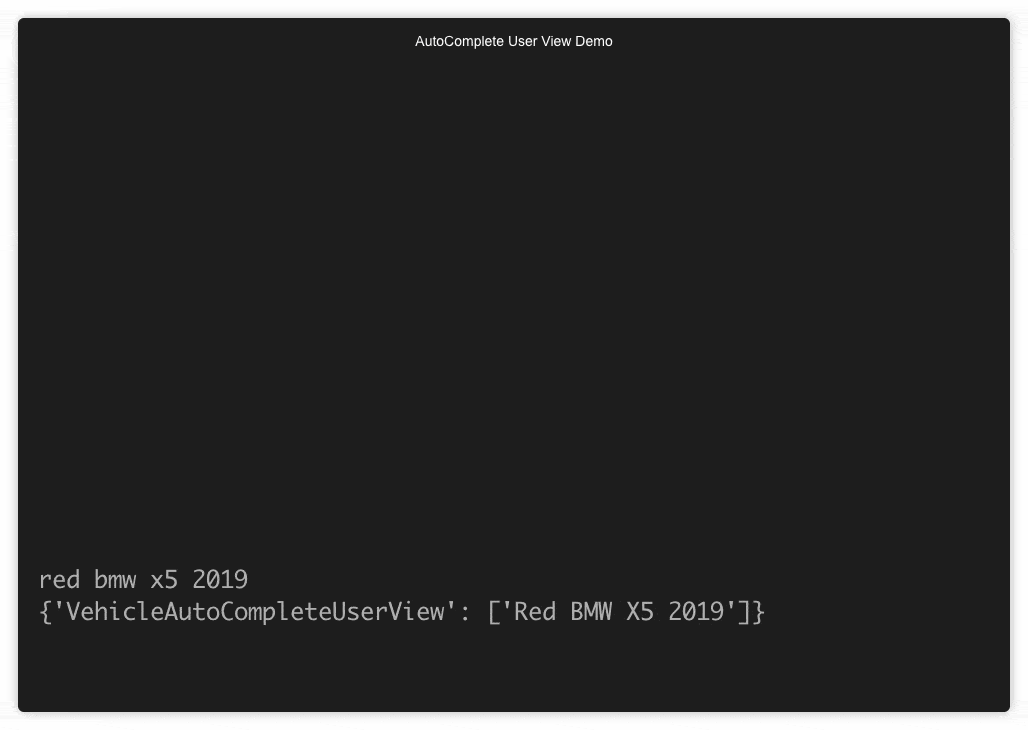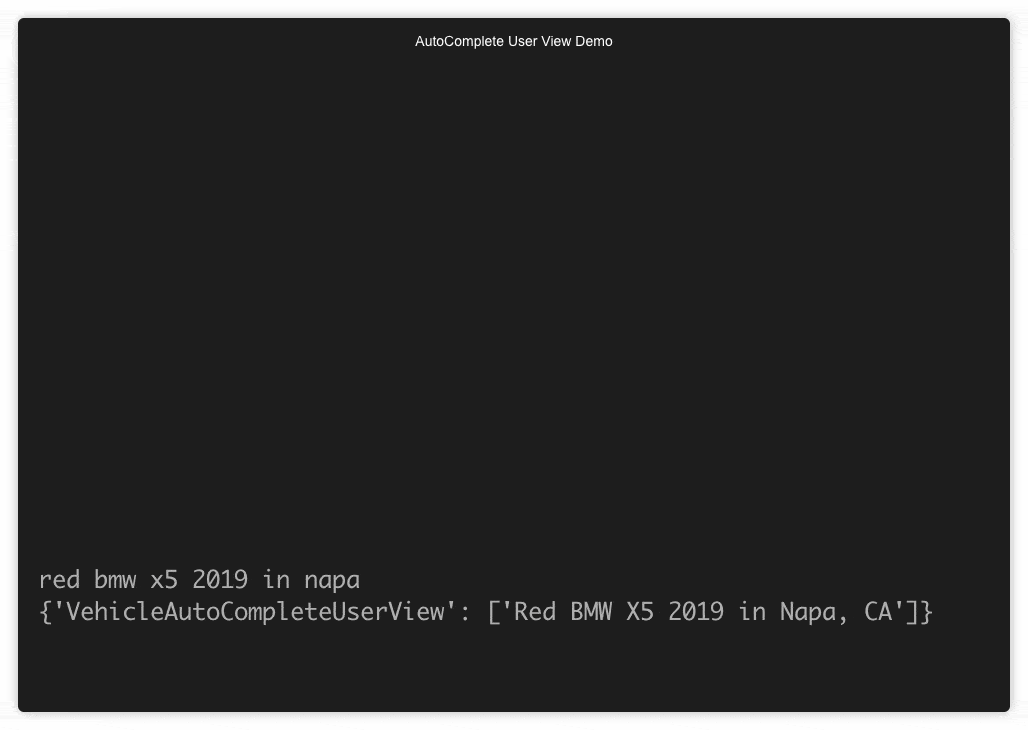
The incremental AND delimited search
Remember that we had two types of search:
- Delimited Search: You type something, hit enter, get results.
- Incremental Search AKA Auto Complete AKA Auto Suggestion.
That’s where I thought, why not turn the DAWG into a FST (Finite-State Transducer) that translates the user entry into Lucene syntax. By doing that the same graph that provides suggestions to the user as they type could also translate the user’s query for a delimited search!
Demo 2

You might be asking, did you not decide to not use Lucene? The answer is I didn’t use it for Autocomplete but we still decided to use it for “delimited search”.
Part 7: The Outcome
Once we switched to fast-autocomplete, here is what we observed:
No more errors and 3-4x performance improvement in autocomplete
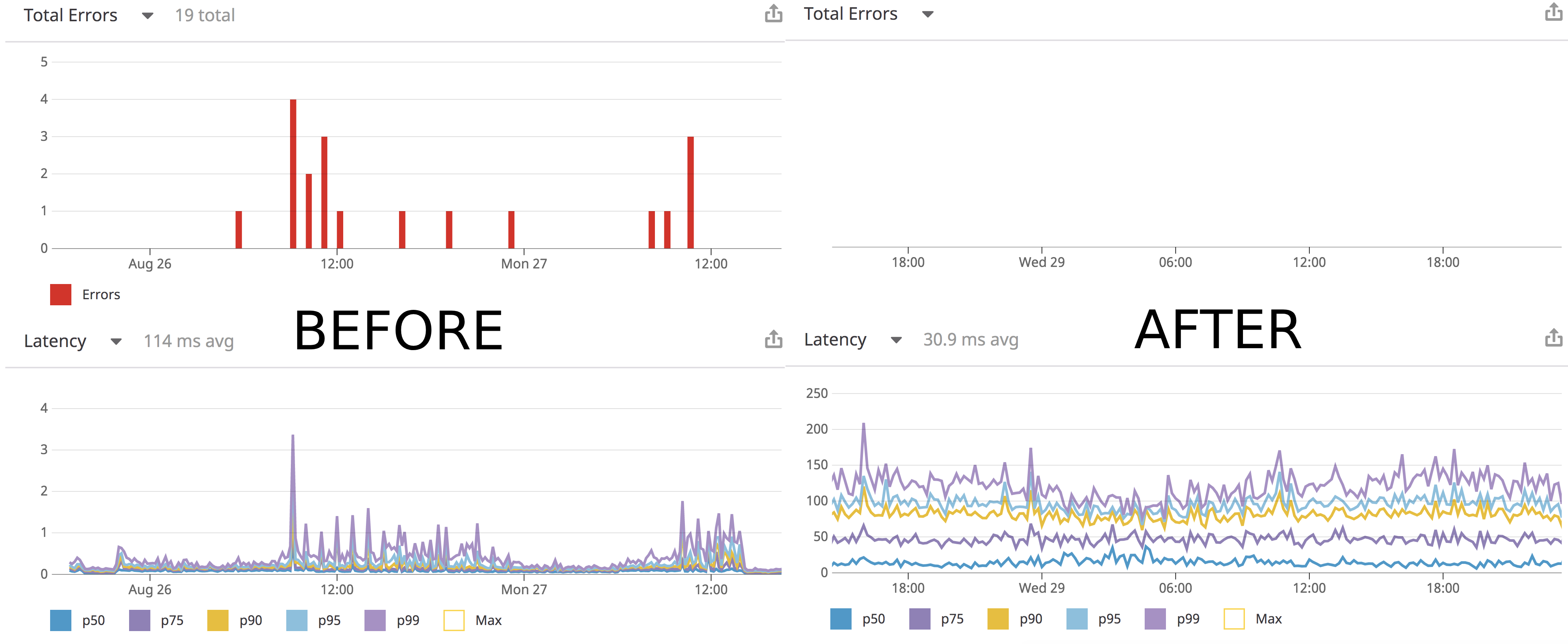
Ok I’m cheating here a little bit. There are still some errors that happen randomly due to network failures and other factors. Unfortunately it is not easy to reproduce those errors. Currently our error rate is 0.0004 errors per each request. The performance boost though has been very tangible.
More user engagement with Autocomplete
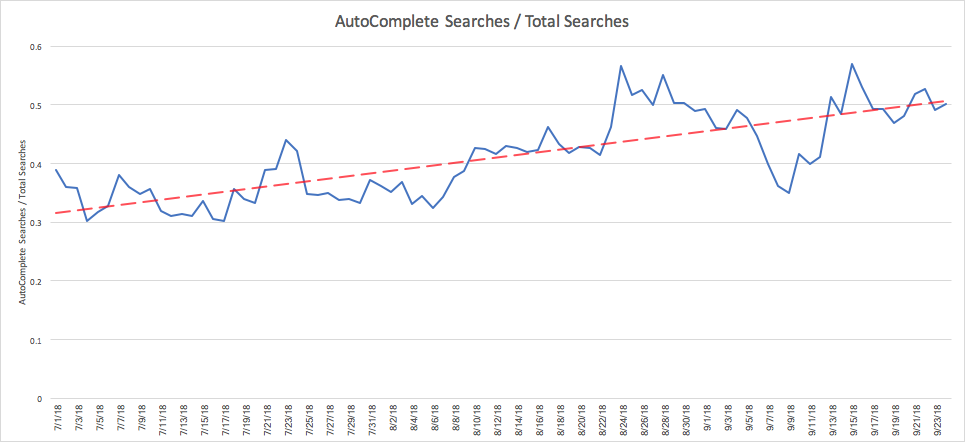
Complex queries
Now we can have user’s type more complex queries!
If you go to fair.com you can see the autocomplete for yourself. Here are 2 snapshots of the autocomplete in action:
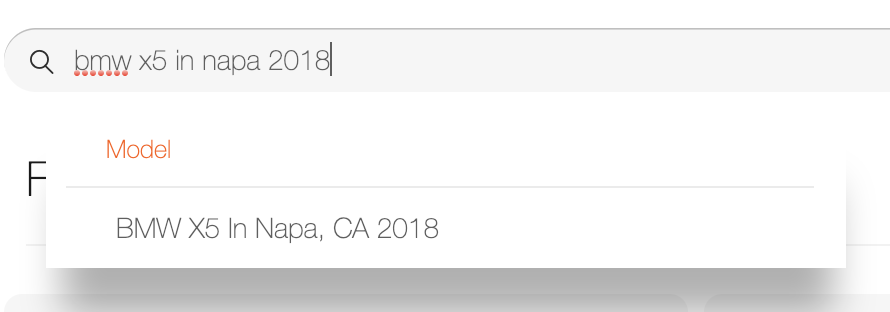
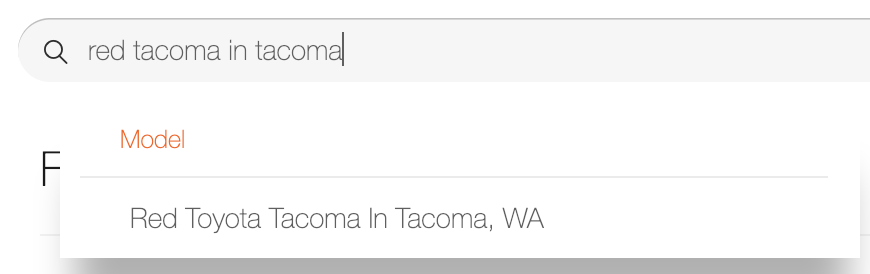
Part 8: Conclusion
Writing our own autocomplete was fun, and ended up with performance gains, customizability and better user engagement. So overall it was a big win and I’m happy that I had the opportunity to pursue it. I hope you learnt something by reading this article too.
Please checkout Fast Autocomplete and if you find it useful, please give it a star. https://github.com/seperman/fast-autocomplete
You can visit fair.com to see the autocomplete in action and maybe even do some car shopping!
Finally I would like to say a big thank you to my colleague John Case who took the time to edit this article and provide constructive feedback.